
Category: Data Engineering
-

สรุปจากงาน Google I/O Connect Beijing 2024 และ GDE Summit (Thai ver.)
บทความนี้เราจะพามาเที่ยวจีนกันค่ะ เอ้ย! พาไปงาน Google I/O Connect ที่ปักกิ่งกัน พ่วงมา GDE Summit ที่ Google Office Beijing กัน Google I/O Connect คืออะไร? Google I/O Connect เป็นซีรี่ส์ที่ต่อเนื่องมาจากงาน Google I/O ค่ะ แล้ว Google I/O คืออะไร ? งาน Google I/O คืองานที่ Google ประกาศเทคโนโลยีใหม่ๆประจำปี จัดที่ Mountain View, Californiaซึ่งในปี 2024 ก็จะมีเรื่องเด่นๆเลยคือ Gemini AI, Firebase Genkit อาจจะคุ้นๆภาพของ Sundar Pichai บนเวที และพ่นคำว่า “AI” เยอะๆ ใช่ค่ะ…
-

6 อุปสรรคที่เด็กผู้หญิงในยุโรปไม่เลือกเรียนต่อ Computer Science
ชวนอ่านสำรวจที่ Google และ Canvas8 ร่วมกันสำรวจและสัมภาษณ์เด็กนักเรียนและผู้นำการศึกษาทั่วยุโรป
-

สอบ Google Cloud Certification: Data Engineer ปี 2024 (ข้อสอบใหม่ Nov 2023)
แชร์การเตรียมตัวและคำแนะนำในการสอบ Google Cloud Certification: Data Engineer ปี 2024 (อัพเดทข้อสอบใหม่ Nov 2023)
-

Introducing Data Lakehouse: Apache Iceberg — Slides!
Slides from #DevFestCloudBangkok2023. Introducing Data Lakehouse: Apache Iceberg
-
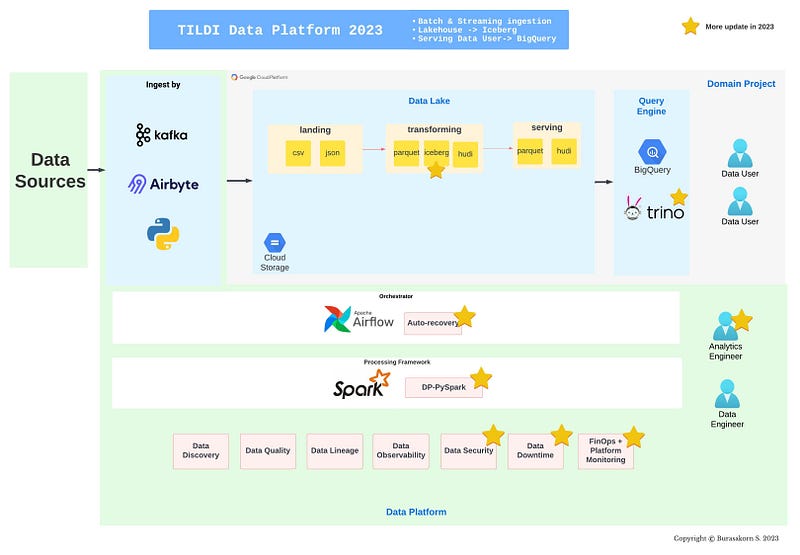
Journey of TILDI Data Engineer in 2023 — การพัฒนา Data Platform อย่างต่อเนื่อง
ในปีที่แล้วเราได้อธิบายว่า Data Engineer ในทีม TILDI ทำอะไรบ้าง ทั้งด้าน tech stack, เครื่องมือที่เราใช้, security และอธิบายถึงคอนเซปต่างๆใน Data Platform ไม่ว่าจะเป็น Data Observability, Data Validation/ Data Quality, Data Monitoring, Data Lineage และ Data Discovery/ Catalog ที่ช่วยให้คนดึงข้อมูลและคนใช้ข้อมูลเองมั่นใจในตัวเนื้อข้อมูลและใช้งานอย่างมีประสิทธิภาพ
-
![[Tutorial] Setting up Budget Alert in GCP — English ver.](https://mesodiar.com/wp-content/uploads/2023/08/40ae4-1cg9upfniizhopmn3wq2zmq.png?w=1024)
[Tutorial] Setting up Budget Alert in GCP — English ver.
Have you ever opened a service on the cloud and accidentally forgot to close it, ending up with charges ?
-
![[Tutorial] Setting up Budget Alert in GCP](https://mesodiar.com/wp-content/uploads/2023/08/setting-up-budget-alert-in-gcp.png?w=1024)
[Tutorial] Setting up Budget Alert in GCP
This article is written in both Thai and English: https://mesodiar.wordpress.com/tutorial-setting-up-budget-alert-in-gcp-english-ver-f134bf21da92 เคยไหมที่เปิด service บน cloud ไปแล้วเผลอลืมปิด โดนชาร์จไปแบบไม่รู้ตัว ? เคยไหมที่ใช้ cloud ไปเยอะเท่าไร billing อัพเดทช้าไม่ทันใจ ไม่รู้ว่าตอนนี้ cost กินไปเท่าไรแล้ว ? บทความนี้เราจะสอนวิธีเซ็ต budget alert flow เมื่อ cost ของการใช้งานสูงกว่า budget ที่กำหนดไว้ flow นี้ก็จะมี action บางอย่าง เช่น ส่ง notification มาหา 1 ครั้งต่อเดือน หรือทำ action บางอย่างแบบ automate ที่เราต้องการแบบมีเงื่อนไข ปกติแล้ว ใน Cloud Billing ตัวมันเองจะสามารถส่ง noti หา…
-

What is Apache Iceberg: Iceberg คืออะไร ทำอะไรได้บ้าง ?
บทความนี้เราจะมาเล่าถึง Apache Iceberg กัน
-

เล่าให้ฟัง FinOps: BigQuery Query Cost Monitoring
ฟังย้อนหลัง: หัวข้อเรื่อง “FinOps: BigQuery Query Cost Monitoring” ใน Kick-off event ของ #ChaiyoGCP season 3
-

FinOps: Our Team’s Journey to Saving on BigQuery Usage (Over $300!)
Journey ตั้งแต่การเริ่ม apply concept เรื่อง FinOps ภายในทีม Data รวมถึงสิ่งที่เราได้ research และจนได้ผลลัพท์ที่ทำให้เราเห็นข้อมูลการใช้งานบน BigQuery จนสามารถลด cost ที่ไม่จำเป็นได้มากกว่า 300$
-

Protect sensitive data in pipeline with Tink and Cloud KMS
IWD 2023: Protect sensitive data in pipeline with Tink and Cloud KMS as Envelope Encryption
-
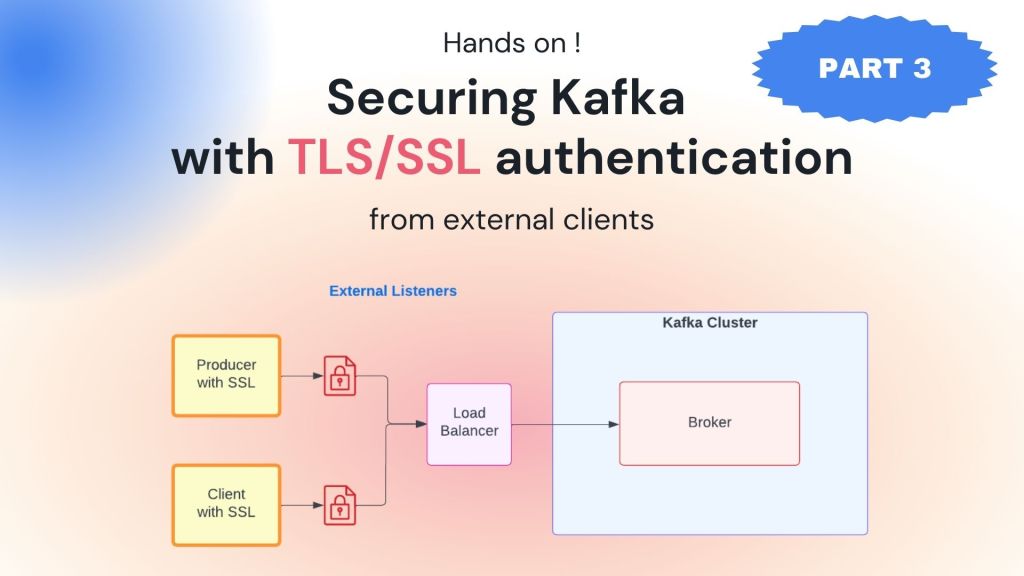
Securing Kafka with TLS/SSL encryption
Kafka secure มากขึ้นได้อย่างไรบ้าง ทำไมต้องคิดเรื่อง security, มี security protocol แบบไหนบ้าง และปรับ Kafka cluster เราให้เป็นแบบ TLS จนไปถึงการทดสอบว่าสามารถ authen และ authorized ผ่านจริงๆ
-

Setting up Kafka with Kafka connect from SQL server to Cloud storage (GCS)
setup Kafka cluster โดยใช้ Strimzi รวมถึง setup Kafka connect เพื่อต่อไปยัง external source ต่างๆเพื่อดึงจาก SQL server เป็น source data ต้นทางโดยเก็บ event จาก Change Data Capture (CDC) แล้วนำไปเก็บที่ sink ปลายทางที่ Google Cloud Storage
-

ความแตกต่างระหว่าง Parallel Computing และ Distributed Computing
Parallel computing vs distributed computing แบบสั้นๆ
-

MapReduce คืออะไร เข้าใจที่มา Hadoop และในด้าน Distributed Computing
MapReduce คืออะไร เข้าใจที่มา Hadoop และในด้าน Distributed Computing
-
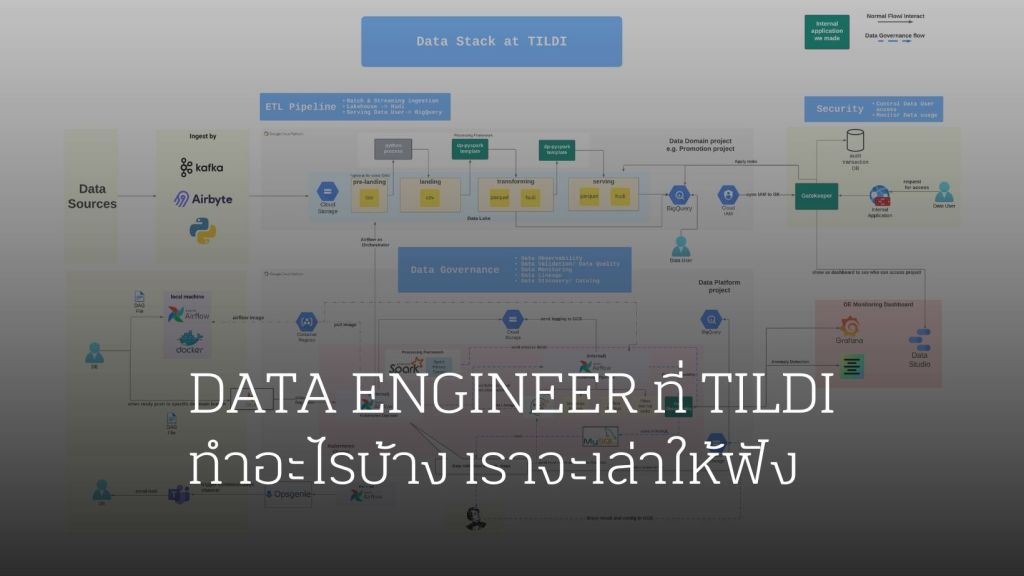
Data Engineer ที่ TILDI ทำอะไรบ้าง เราจะเล่าให้ฟัง
ใน TILDI ของเรา ทีม Data Engineer ของเราไม่ได้มีหน้าที่แค่เป็นคนขนข้อมูลให้, transform ข้อมูลให้ หรือวาง pipelineให้ data user เพียงอย่างเดียว นั่นเป็นแค่เพียงส่วนหนึ่งของงานเราเท่านั้น
-

Spark คืออะไร เกิดขึ้นมาได้ยังไง หัวข้อที่ Data Engineer ต้องรู้
บทความนี้เราจะมาเล่าหัวข้อหนึ่งที่สำคัญในสาย Data Engineer มากๆ คือ Spark นั่นเอง
-

ลองสร้าง SFTP server ให้ Airflow ไปวางไฟล์ให้หน่อย
จำลองสร้าง SFTP server กัน โดย use case ของเราคือเราอยากดึงข้อมูลจาก BigQuery ไปวางไว้ที่ Google Cloud Storage
-

Building Data Lakehouse: Apache Hudi คืออะไร ทำความเข้าใจ Hudi กัน
Apache Hudi คืออะไร ทำอะไรได้บ้าง
-

มาทำ Data Lineage โดยใช้ DataHub กัน ! (พร้อมวิธีทำอย่างละเอียดและตัวอย่าง)
เราจะเริ่มเล่าตั้งแต่ Data Lineage คืออะไร จนถึงตัวอย่าง implementation จริงในการสร้าง Data Lineage จริงที่เราใช้
-

ACID ใน database คืออะไร
ACID ใน database คืออะไร คือกรดรึเปล่า เย้ยย
-

Distributed data EP. 1: Replication
ทำไมเราถึงอยาก distributed data และเรื่องอะไรที่เราจำเป็นต้อง concern บ้าง ?
-
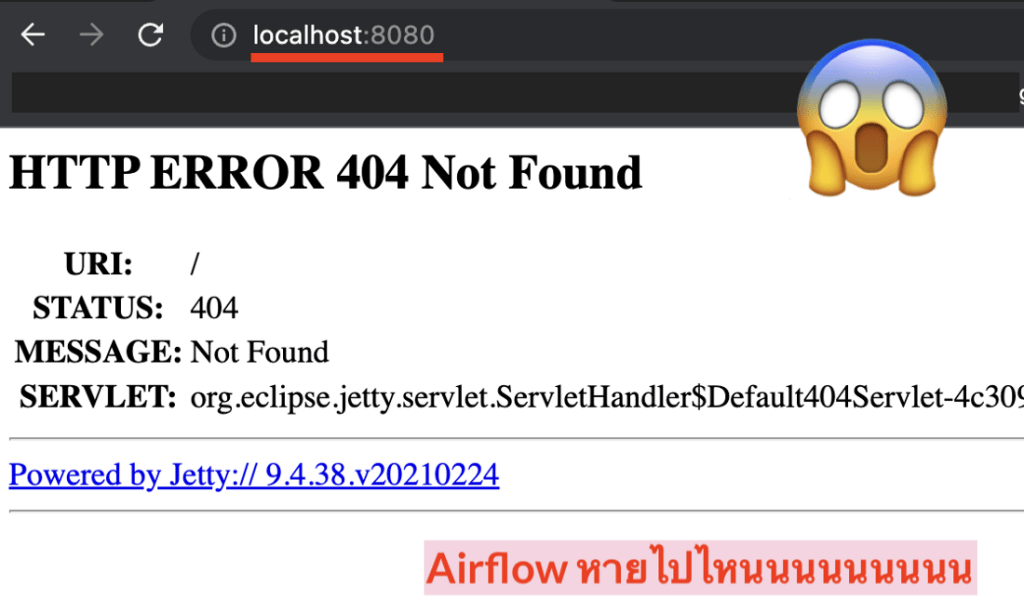
ตามหาว่า program ไหนแย่ง port ไป ด้วยคำสั่ง ps
เมื่อหลายวันก่อน เรากำลังอัพ Airflow เพื่อจะเล่นบนเครื่อง local ของเรา ในขณะที่เรากำลังเข้า localhost:8080 ซึ่งเป็นทางเข้าและ port ปกติของ webserver ของ Airflow ปรากฏว่าเราหน้าตาของ Airflow เราเปลี่ยนไป อ้าก
-

Intro to Apache Kafka Universe: Kafka คืออะไร ?
Kafka คืออะไร เราจะมาเล่าตั้งแต่ Streaming data คืออะไรและ concept ต่างๆใน Kafka กัน
-

เทคนิคการเรียนรู้ของฉัน (ในการเป็น Data Eng และอื่นๆ)
เมื่อหลายวันก่อนเรามีโอกาสได้ไปสอน Data Engineer 101 เป็น live session เสริมในคอร์สของ DataRockie มา ในตอนท้ายคาบ เรามีแชร์เทคนิคการเรียนรู้เพื่อตอบคำถาม “How do I become Data Engineer?” ในพาร์ทสุดท้าย ซึ่งฟีดแบ็คค่อนข้างดีเลย เลยมาฉุกคิดได้ว่า ถ้าเราแชร์สิ่งนี้เป็นข้อความด้วยก็คงจะดีนะ? เนื่องด้วยเทคนิคของเราไม่ได้ตายตัวว่าจะต้องเป็น Data Engineer เท่านั้น แต่พูดถึงโดยทั่วไป ที่สามารถ adapt ได้กับสายงานอื่นๆได้ เพียงแต่จะยกตัวอย่างจากอาชีพที่เราทำอยู่คือ Data Engineer นั่นเอง การเรียนรู้ของเราต่างกัน เมื่อหลายปีมาแล้ว เราเคยอ่านหนังสือชื่อ Managing Oneself ของ Peter F. Drucker เป็นหนังสือที่สอนเกี่ยวกับการจัดการของตัวเอง และตั้งคำถามให้กับตัวเอง หลายบทอาจจะมีความเก่ามากแล้วเพราะหนังสือถูกเขียนไว้นาน แต่บางบทก็ยังคงสามารถ adapt ใช้ได้ในปัจจุบัน มีบทหนึ่งที่เราชอบๆและประทับใจจนถึงทุกวันนี้ เราอาจจะคำพูดไม่ได้เป๊ะ แต่บทนั้นเล่าว่า การเรียนรู้ของแต่ละคนต่างกัน โดยเราเล่าสั้นๆและขอแบ่งออกเป็น 3…
-

เข้าใจ Data Warehouse, Data Lake และ Data Lakehouse ฉบับมือใหม่
มาเข้าใจ Data Warehouse, Data Lake และ Data Lakehouse โดยเราเล่าที่มาที่ไปกันเลย
-

5 main database genres and CAP theorem
“An individual song may share all of the same notes with other songs. but some are more appropriate for certain uses” — Seven weeks of seven databases book
